AWS Transcribe#
AWS Transcribe is a service that recognizes speech in your audio or video and transcribes that speech into text.
Credentials
You can find authentication information for this node here.
Basic Operations#
Transcription Job - Create a transcription job - Delete a transcription job - Get a transcription job - Get all transcriptions job
Example Usage#
This workflow allows you to create transcription jobs for all your audio and video files stored in AWS S3. You can also find the workflow on n8n.io. This example usage workflow uses the following nodes. - Start - AWS S3 - AWS Transcribe
The final workflow should look like the following image.
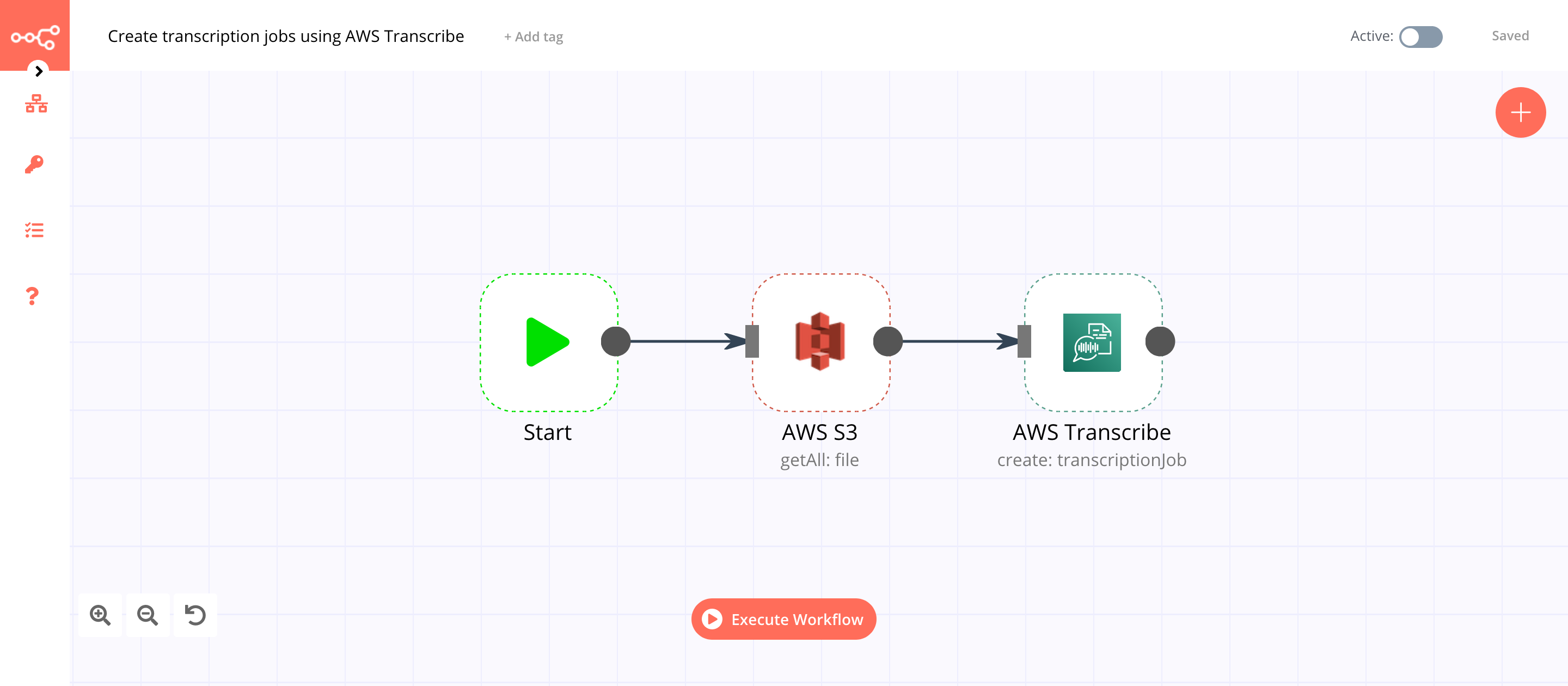
1. Start node#
The start node exists by default when you create a new workflow.
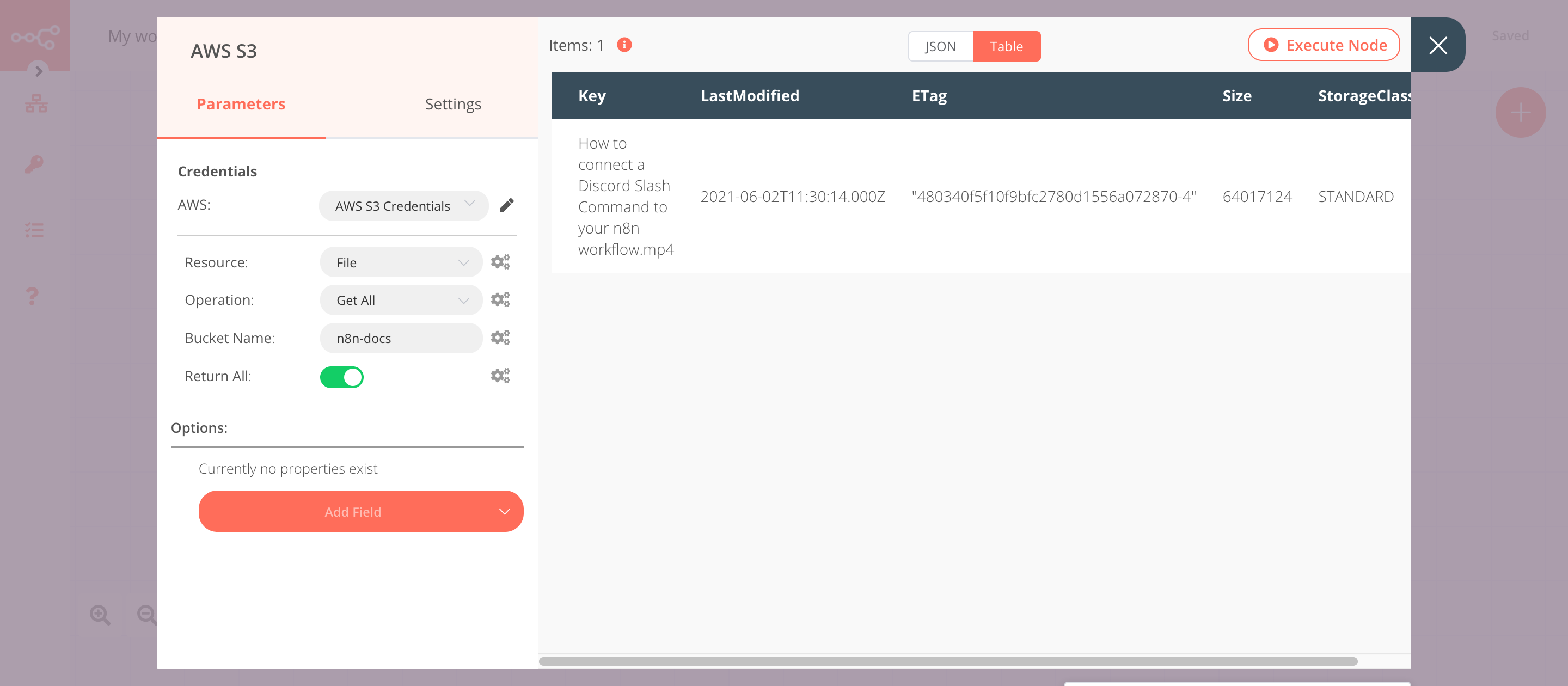
2. AWS S3 node (getAll: file)#
This node will retrieve all the files from an S3 bucket you specify.
- First of all, you'll have to enter credentials for the AWS S3 node. You can find out how to do that here.
- Select 'Get All' from the Operation dropdown list.
- Enter the bucket name in the Bucket Name field.
- Toggle Return All to
true. This option will return information on all the files stored in the S3 bucket. - Click on Execute Node to run the node.
In the screenshot below, you will notice that the node returns information of all the files stored in the bucket you specified.
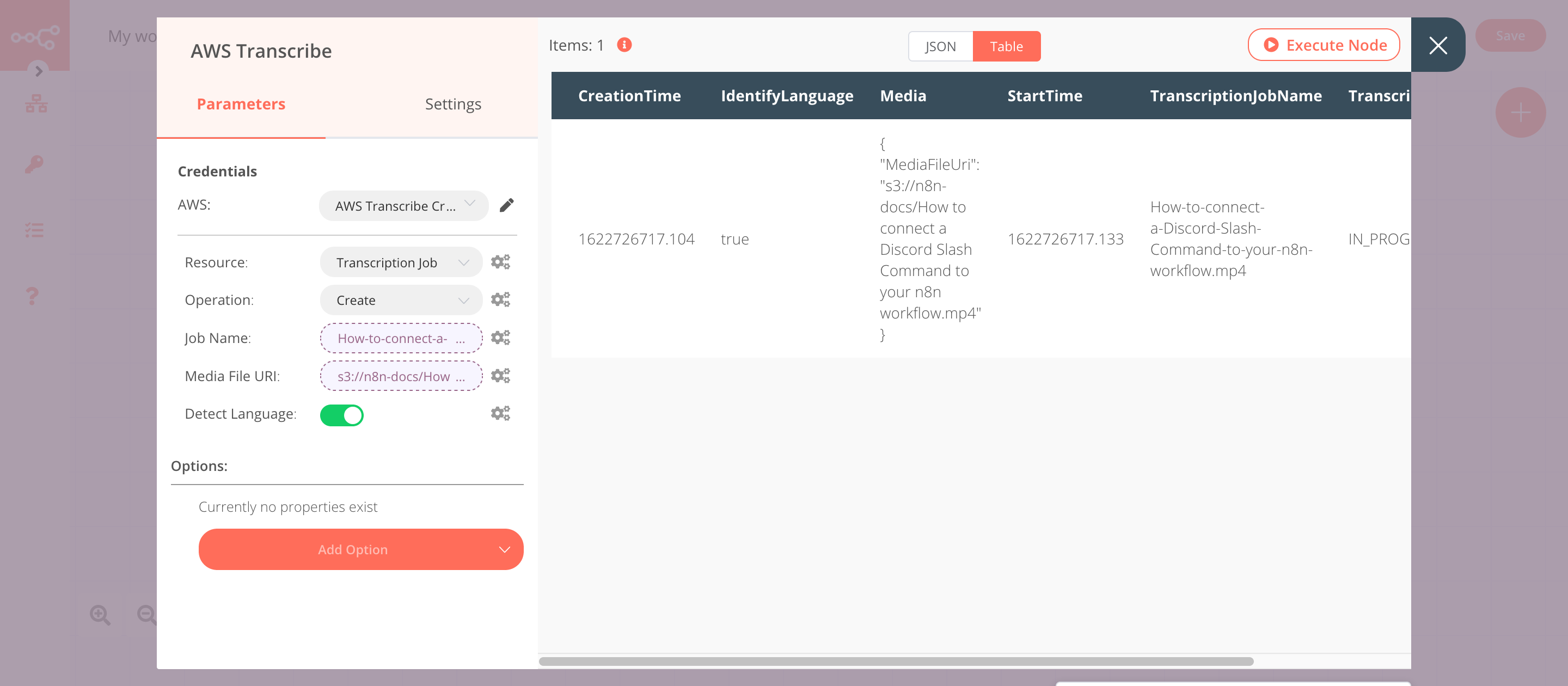
3. AWS Transcribe node (create: transcriptionJob)#
This node will create a transcription job for the files that get returned by the previous node.
- Select the credentials that you entered in the previous node.
- Click on the gears icon next to the Job Name field and click on Add Expression.
- Enter
{{$json["Key"].replace(/\s/g,'-')}}in the Expression field. The code snippet fetches the name of the file and replaces the white-spaces with a hyphen (-). - Click on the gears icon next to the Media File URI field and click on Add Expression.
- Enter
s3://{{$node["AWS S3"].parameter["bucketName"]}}/{{$json["Key"]}}in the Expression field. - Toggle Detect Language to
true. - Click on Execute Node to run the node.
In the screenshot below, you will notice that the node creates a transcription job for the files stored in an S3 bucket.