HTML Extract#
The HTML Extract node is useful to extract the HTML content of a webpage.
Node Reference#
- Source Data: This field specifies if HTML should be read from binary or JSON data. In this dropdown list, there are two options.
- Binary
- JSON
- JSON Property: The name of the JSON property in which the HTML (from which to extract the data) can be found. This field is displayed when 'JSON' is selected in the Source Data field.
- Binary Property: The name of the binary property in which the HTML (from which to extract the data) can be found. This field is displayed when 'Binary' is selected in the Source Data field. The property can either contain a string or an array of strings.
- Extraction Values:
- Key: The key under which the extracted value should be saved.
- CSS Selector: The CSS selector to use.
- Return Value: The kind of data that should be returned. In this dropdown list there are four options.
- Attribute: Get an attribute value like 'class' from an element.
- Attribute: The name of the attribute to return the value of.
- HTML: Get the HTML that the element contains.
- Text: Get only the text content of the element.
- Value: Get the value of an input, select, or textarea.
- Attribute: Get an attribute value like 'class' from an element.
- Return Array: Returns the values as an array so that if multiple ones are found, they also get returned separately. If not set, all values will be returned as a single string.
- Options:
- Trim Values: Removes all spaces and newlines from the beginning and end of the values.
Example Usage#
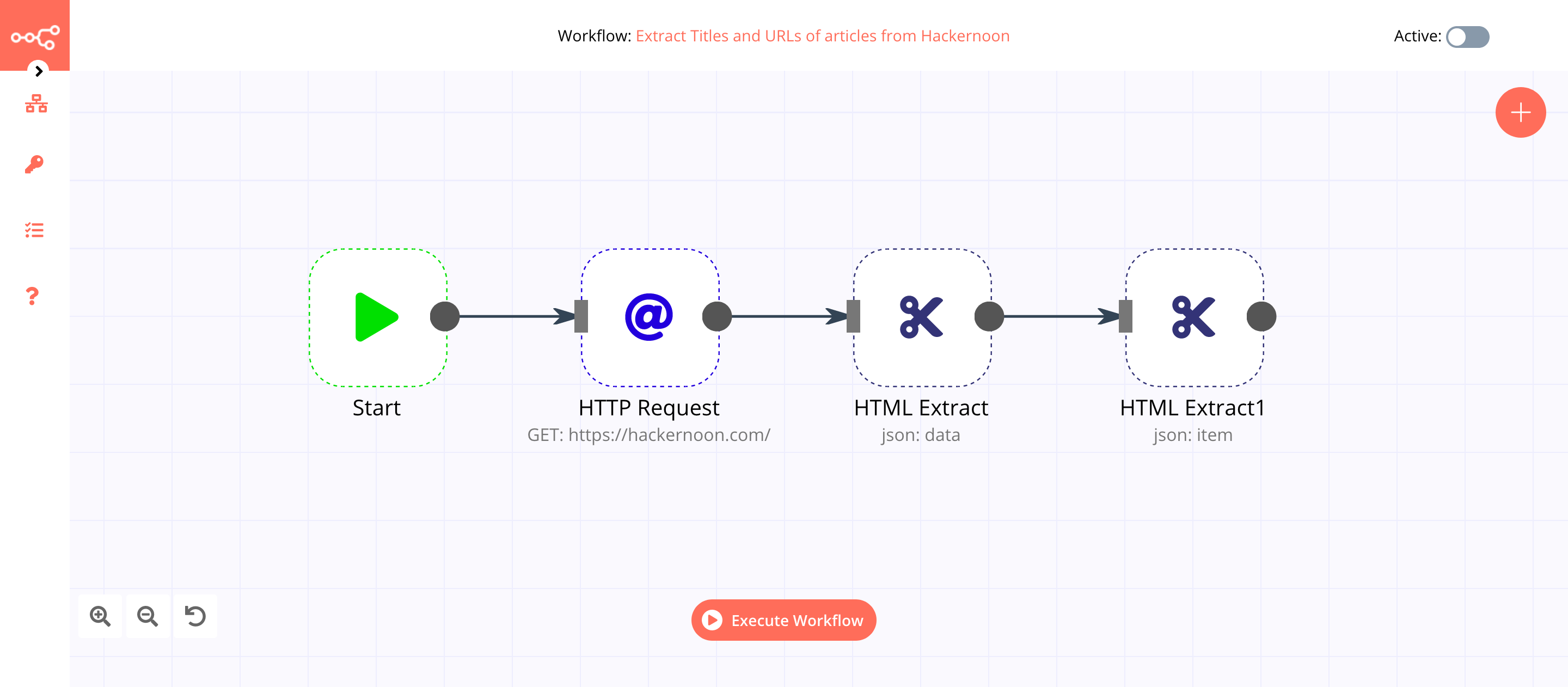
This workflow allows you to extract titles and URLs of all the articles from the Hackernoon homepage using the HTML Extract node. You can also find the workflow on n8n.io. This example usage workflow uses the following nodes. - Start - HTTP Request - HTML Extract
The final workflow should look like the following image.
1. Start node#
The start node exists by default when you create a new workflow.
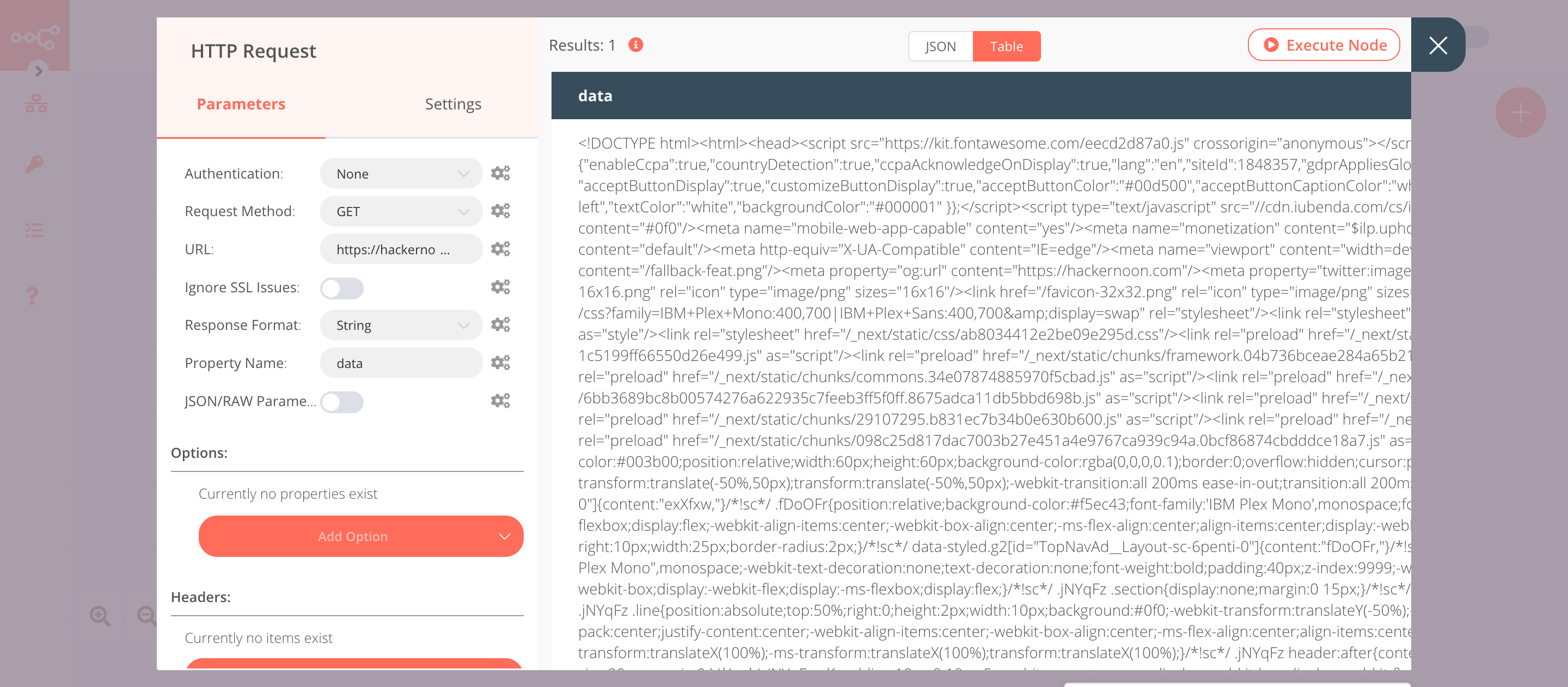
2. HTTP Request node (GET)#
- Enter
https://hackernoon.comin the URL field. - Select 'String' from the Response Format dropdown list.
- Click on Execute Node to run the node.
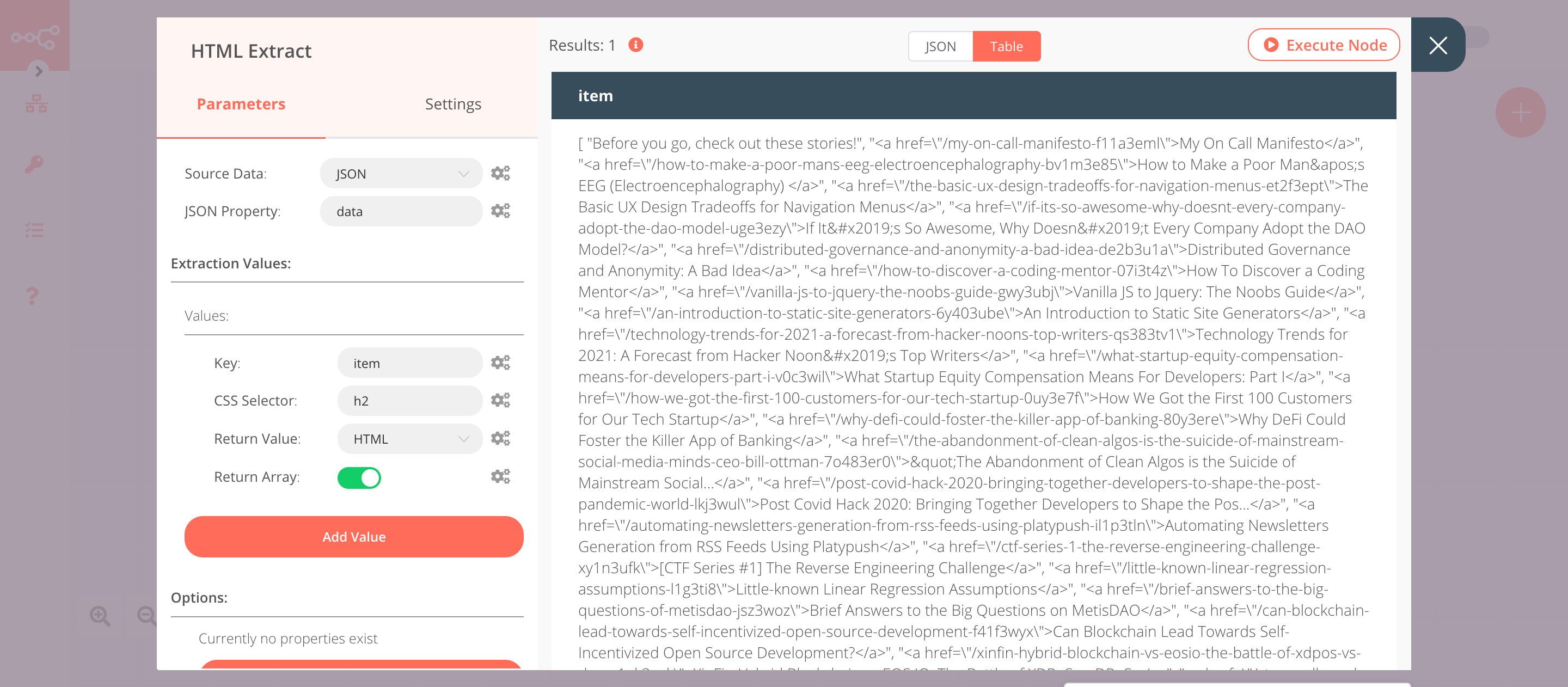
3. HTML Extract node (json: data)#
- Click on the Add Value button.
- Enter
itemin the Key field. - Enter
h2in the CSS Selector field. - Select 'HTML' from the Return Value dropdown list.
- Toggle Return Array to true.
- Click on Execute Node to run the node.
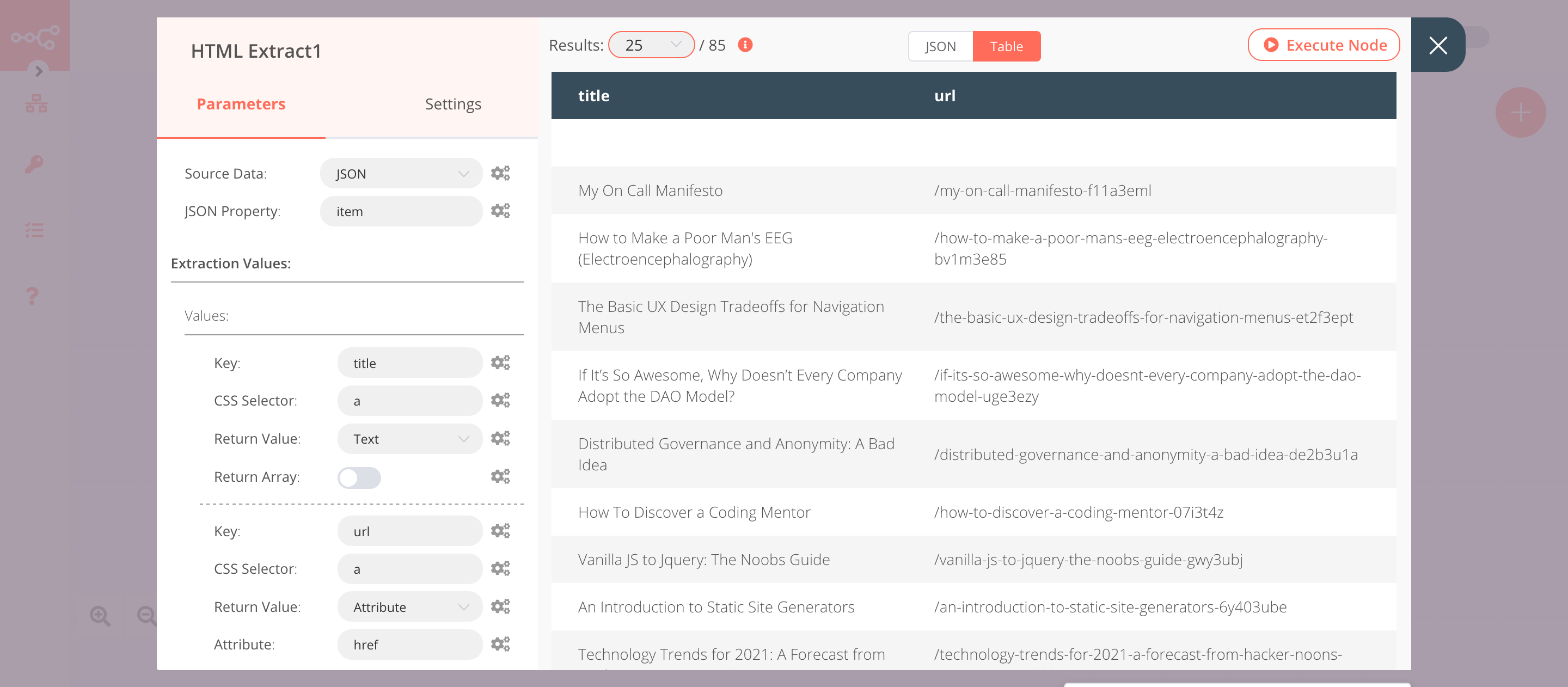
4. HTML Extract1 node (json: item)#
- Enter
itemin the JSON Property field. - Click on the Add Value button.
- Enter
titlein the Key field. - Enter
ain the CSS Selector field. - Click on the Add Value button.
- Enter
urlin the Key field. - Enter
ain the CSS Selector field. - Select 'Attribute' from the Return Value dropdown list.
- Enter
hrefin the Attribute field. - Click on Execute Node to run the node.